Loi sur les droits voisins de la presse : une loi déconnectée de la réalité
Opinions et politique –Selon les sociétés de presse, les extraits de contenu d'un article sont un manque à gagner
Le 26 mars dernier, une directive très controversée (en tout cas dans la sphère populaire) a été adoptée au Parlement européen. Cette directive a pour sujet les droits d'auteur dans la société du numérique : elle est venue poser un cadre juridique sur beaucoup de zones grises et de notions non réglementées jusque là. Il s'agit d'une directive européenne, ce qui signifie qu'une loi l'appliquant doit être adoptée dans tous les états membres, d'ici deux ans (le temps que les différentes nations puissent transcrire le texte dans la juridiction locale).
Cette directive fut très controversée, notamment à cause des articles 11 et 13 (devenus articles 15 et 17), qui prévoient respectivement – dans les grandes lignes – une taxe sur les extraits d'article de presse pour les sites qui en utilisent, et un cadre juridique ainsi que des sanctions sévères concernant la mise en ligne de contenus protégés par le droit d'auteur. C'est de ce quinzième article, et plus précisément de sa transposition française, dont je vais parler ici.
La loi sur les droits voisins de la presse, qui a été définitivement adoptée il y a quelques jours à l'Assemblée Nationale et qui va entrer en application dans trois mois, va imposer à tout site Internet reprenant le contenu d'un article de presse (qu'il s'agisse du titre, ou du corps de l'article), de verser une redevance aux sociétés de presse propriétaires de l'article. Plus précisément, par défaut, la loi interdira aux sites de reprendre le contenu des articles de presse, à moins qu'un accord ne soit établi entre l'organisme de presse et le site en question, accord qui imposera le paiement d'une redevance.
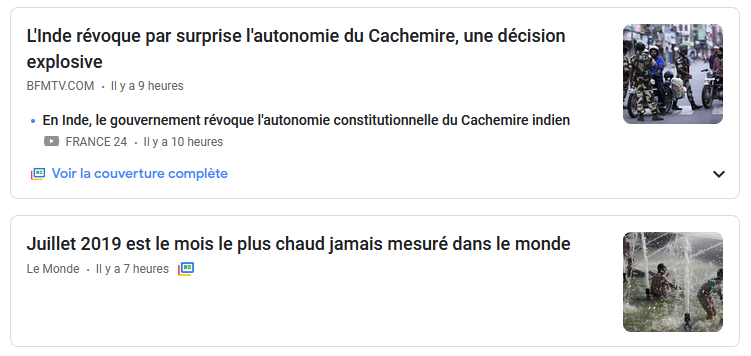
Pourquoi ? Car selon les sociétés de presse, les extraits d'articles sur d'autres sites constituent un manque à gagner pour elles. En effet, il arrive que le titre ou le résumé d'un article soit suffisamment complet pour que le lecteur pense qu'il a acquis l'information, et ne clique pas pour se rendre sur le site du journal en question : journal qui ne pourra donc pas profiter du revenu généré par les publicités ou d'un éventuel article acheté, entre autres.
Une exception est cependant prévue : la rémunération ne sera pas exigible lorsque le titre ou le résumé de l'article n'est pas suffisant pour se passer de la lecture de l'article. La loi parle de trois choses : les hyperliens, les mots isolés, et les « très courts extraits ». Ce critère est cependant flou : à partir de quand un extrait deviendra t-il suffisament complet pour ne pas avoir à lire l'article ? D'autant plus que, comme nous allons le voir plus bas, ce sont très souvent les journaux eux-mêmes qui fournissent ces titres et descriptions.
Ou quand la mauvaise foi et la malhonnêteté atteignent des sommets
Cette loi est un non-sens total, et ceci pour plusieurs raisons.
Tout d'abord, l'acteur qui est principalement visé par cette loi – c'est à peine implicite – est bien sûr Google Actualités. Comme on peut le voir sur l'exemple ci-dessus, Google Actualités reprend la quasi-totalité des articles des journaux français, en incluant le titre (qui très souvent se suffit à lui-même, et résume bien l'article), et éventuellement la description de l'article. Avec cette loi, Google Actualités devra donc payer les journaux afin de continuer à faire cela (ce qu'il ne fera probablement pas, comme je l'explique plus bas).
Google Actualités, selon les sociétés de presse européennes, serait donc une nuisance, un obstacle, un acteur qui leur cause du manque à gagner. Je ne sais pas comment ils arrivent à cette conclusion, mais c'est une opinion qui est objectivement aberrante.
En effet, Google Actualités est, au contraire, quelque chose qui selon moi profite à tout le monde : lecteurs, sociétés de presse et Google lui-même. Les lecteurs ont accès à la liste de presque tous les articles que la presse française publie, ce qui rend leur collecte d'informations plus rapide, et qui le poussera à cliquer sur les articles dont le titre l'intéresse. Les sociétés de presse en profitent aussi, car c'est un très gros marché potentiel, qui est susceptible de générer bien plus de clics sur leurs articles que s'ils restaient dans leur coin.
Ainsi, selon ces sociétés de presse, il serait plus avantageux que Google Actualités n'existe pas, plutôt que peut-être un lecteur sur deux ne clique pas sur leur article car il considère que l'essentiel de l'information était déjà dans la prévisualisation.
C'est d'autant plus malhonnête que ce sont ces sociétés qui choisissent elles-mêmes d'être sur Google Actualités. Par défaut, Google référence les sites – donc les journaux – et les place dans son index, mais il est très facile de lui ordonner de ne pas le faire, et de ne pas apparaître sur Google.
Vous vous demandez alors : mais si ces sociétés considèrent que Google Actualités lui font plus de mal que de bien, pourquoi ne se sont-elles pas retirées de Google d'elles-mêmes ? La réponse, nous ne l'aurons pas, mais je pense que nous l'avons tous comprise.
En résumé, ces sociétés de presse désirent non seulement que Google les indexe, et qu'elles soient payées pour cela. Tout de même très illogique : c'est comme si le Routard devrait payer un hôtel pour le citer dans son guide, au motif que « bah, certaines personnes peuvent ne pas avoir envie de venir dans l'hôtel ». Si vous voulez mon avis, cela devrait plus être l'inverse : c'est l'hôtel qui devrait payer pour apparaître dans le Routard ! (attention, je ne dis pas que cela devrait être le cas, je dis juste que c'est beaucoup plus logique.)
Je n'ai fait que parler de Google Actualités jusque là, mais cette loi s'appliquera à tous les sites. À peu près tout le monde sera touché : blogs, sites d'information, sites professionnels... et également les réseaux sociaux. Ah, d'ailleurs, parlons-en des réseaux sociaux.

Cela n'aura échappé à personne, les journaux utilisent de plus en plus les réseaux sociaux pour faire parler d'eux, et bien sûr de leurs articles.
Du coup, s'ils mettent leurs articles d'eux-mêmes, de manière active, sur les réseaux sociaux, ils ne peuvent pas prétendre à une redevance, n'est-ce pas ? Perdu ! Il n'y a pas d'exception pour les réseaux sociaux : même si ce sont eux qui postent l'article, Facebook devra les payer tout de même pour faire apparaître leur publication.
Vous voyez le titre de l'article, sur la capture d'écran ? On pourrait se dire que si le titre apparaît dans la publication, cette taxe est peut-être justifiée : vu que Facebook doit « creuser » dans leur article pour générer le titre, Facebook essaye de générer un titre le plus complet possible, ce qui pourrait dissuader le lecteur de cliquer dessus.
Mais en réalité, ce n'est pas Facebook qui génère le titre. C'est le journal qui spécifie lui-même quel titre et quelle description devraient apparaître dans une prévisualisation, dans le code source de la page.
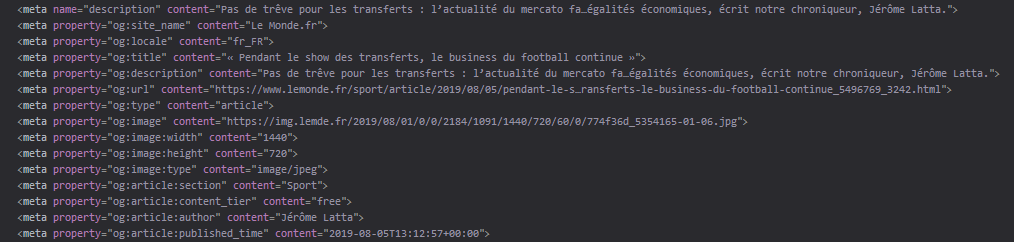
Donc, si je résume :
- Les sociétés de presse se sentent lésées que des extraits de leur article apparaissent sur des sites Internet, et demandent une compensation.
- Ces sites Internet, en réalité, font bien plus de bien que de mal à ces sociétés, car ils apportent du trafic sur leurs journaux sans contrepartie financière. (Je rappelle qu'on ne parle ici que d'extraits d'articles de presse gratuits : ce n'est pas une copie de l'article entier, ni même un extrait d'un article payant par exemple)
- Ces journaux choisissent eux-mêmes d'apparaître sur les sites sus-cités, parfois même en postant leurs propres articles dessus de manière active.
- Ce sont les journaux eux-mêmes qui génèrent les titres et les descriptions, « spoilant » ainsi d'eux-mêmes leurs propres articles.
Comme on dirait dans le langage populaire : avec cette loi, ils ont eu le beurre, l'argent du beurre, et... la crémière ! (pour rester poli).
Une loi probablement vouée à l'échec
Le rêve des sociétés de presse serait d'obtenir un beau tas d'argent pour que la plupart des gros sites puissent les indexer. D'ailleurs, la loi française prévoit cela : elle s'est même occupée de la question « à qui doit aller l'argent, précisément ? ». Ainsi, il est prévu qu'une part significative de l'argent récolté par ces redevances aille directement dans la poche des journalistes (ceux qui écrivent réellement les articles, par opposition aux directeurs et aux sociétés de presse).
Cependant, il y a un très grand risque que cela ne se passe pas comme cela. En effet, il y a plusieurs exemples historiques qui ne vont pas dans ce sens.
Quelques années en arrière, l'Espagne et l'Allemagne avaient aussi écrit et appliqué une loi similaire, à l'échelle nationale. Elle prévoyait grosso modo la même chose : si Google indexait des articles de journaux, alors il devait payer les sociétés de presse.
Devinette : qu'est-ce qui a bien pu se passer ?
- Réponse A : Google s'est plié à la loi et a passé des accords avec les sociétés de presse pour pouvoir continuer à indexer leurs articles, moyennant rémunération.
- Réponse B : Google a refusé de payer et a fermé Google Actualités dans le pays, privant ainsi les journaux de cette rémunération attendue, ainsi que d'une très grande source de trafic. Les journaux n'ont pas réagi.
- Réponse C : Google a refusé de payer et a désindexé tous les journaux qui voulaient cette redevance. Ces derniers ont constaté une très grande chute de leur trafic, ainsi que de leurs revenus. Ils sont par la suite revenus vers Google pour leur demander d'indexer leurs articles à nouveau, cette fois sans contrepartie (retour au statu quo)
- Réponse D : Google a indexé les articles quand même, sans payer. Des actions judiciaires ont été entreprises contre Google, mais après tout, comme ils ont de l'argent, ils peuvent payer...
Voici la réponse : en Espagne, réponse B. En Allemagne, réponse C (voir la section 5)
Si vous cliquez sur le deuxième lien du spoiler ci-dessus, vous constaterez qu'il s'agit d'un rapport venant du Sénat. Même les sénateurs semblent avoir compris que cette loi allait aller droit dans le mur...
Mon pronostic ? Je parierais donc pour la réponse C. Sachant que cette loi va s'appliquer dans trois mois, et que tous les pays européens suivront par la suite, je vous conseille de faire des réserves de popcorn, cela promet d'être amusant.
Le véritable objectif de cette loi : faire cracher Google ?
Au vu du non-sens qu'est cette loi, sur tous les points, on se demanderait presque si son objectif n'était pas autre.
Je ne sais pas ce que vous en pensez, mais pour moi, ce genre de loi est clairement orienté contre les GAFA, à tel point qu'on pourrait se demander s'il ne s'agit pas secrètement d'une loi « anti GAFA ». D'ailleurs, lors des débats et du vote au parlement européen, les députés ont principalement parlé d'une « victoire contre les multinationales américaines », ce qui est plutôt desespérant quand on sait que l'article 17 pourraît au contraire renforcer leur position. Même José Bové s'est permis un tweet dans ce sens...
Attention, que cela soit bien clair : je ne dis pas que les GAFA, et tout particulièrement Google, sont absolument purs et sans reproche. Ce qu'ils font en terme de vie privée est plutôt malsain, ils font de l'optimisation fiscale en masse, ils font également énormément de lobbying et appliquent, d'une certaine manière, le soft power américain sur l'Europe (avec leur politique de filtrage de contenus).
Mais ces problèmes doivent être réglés avec des lois prévues pour cela (telles que la « taxe sur les géants du numérique » qui a été votée il y a quelques jours à l'Assemblée Nationale, ou le RGPD qui est pour le coup une très bonne directive européenne), et non pas avec des textes de loi ciblant indirectement mais prioritairement les GAFA, dans des apparences qui ressemblent beaucoup à un caprice de la part de l'Europe visant à faire grimacer les GAFA et les grandes entreprises extra-européennes du numérique.
aucun commentaire